
Changelog
This page summarizes the changes and improvements to Skwiz.

10 Apr 2026
Views + Validate next
We've added two features to make working through your inbox queue faster and less repetitive.
Views
You can now save combinations of inbox filters and columns as a view.
Views can be set as your default so your inbox opens exactly the way you want it. You can also share views with your team, so everyone can work from the same configuration without having to set it up individually.
Views are separate for split & classify and extract.
Validate next
When you validate a document, Skwiz now automatically opens the next document in your current view.
The next document is determined by the view and sorting you were using when you opened the current document. Skwiz will skip documents that are locked or already validated.
This behavior can be disabled at the tenant level under Document settings > Workflow.
19 Mar 2026
Roles, document locking, and a clearer Inbox flow
Roles, document locking, and a clearer Inbox flow
We’ve introduced a few updates to make collaboration in Skwiz easier and give teams a clearer overview of what needs to be worked on.
This release adds custom roles and permissions, document locking during review, and an updated Inbox that better reflects the document workflow from splitting and classification to extraction and validation.
Roles and permissions
You can now create custom roles and define which permissions each role should have.
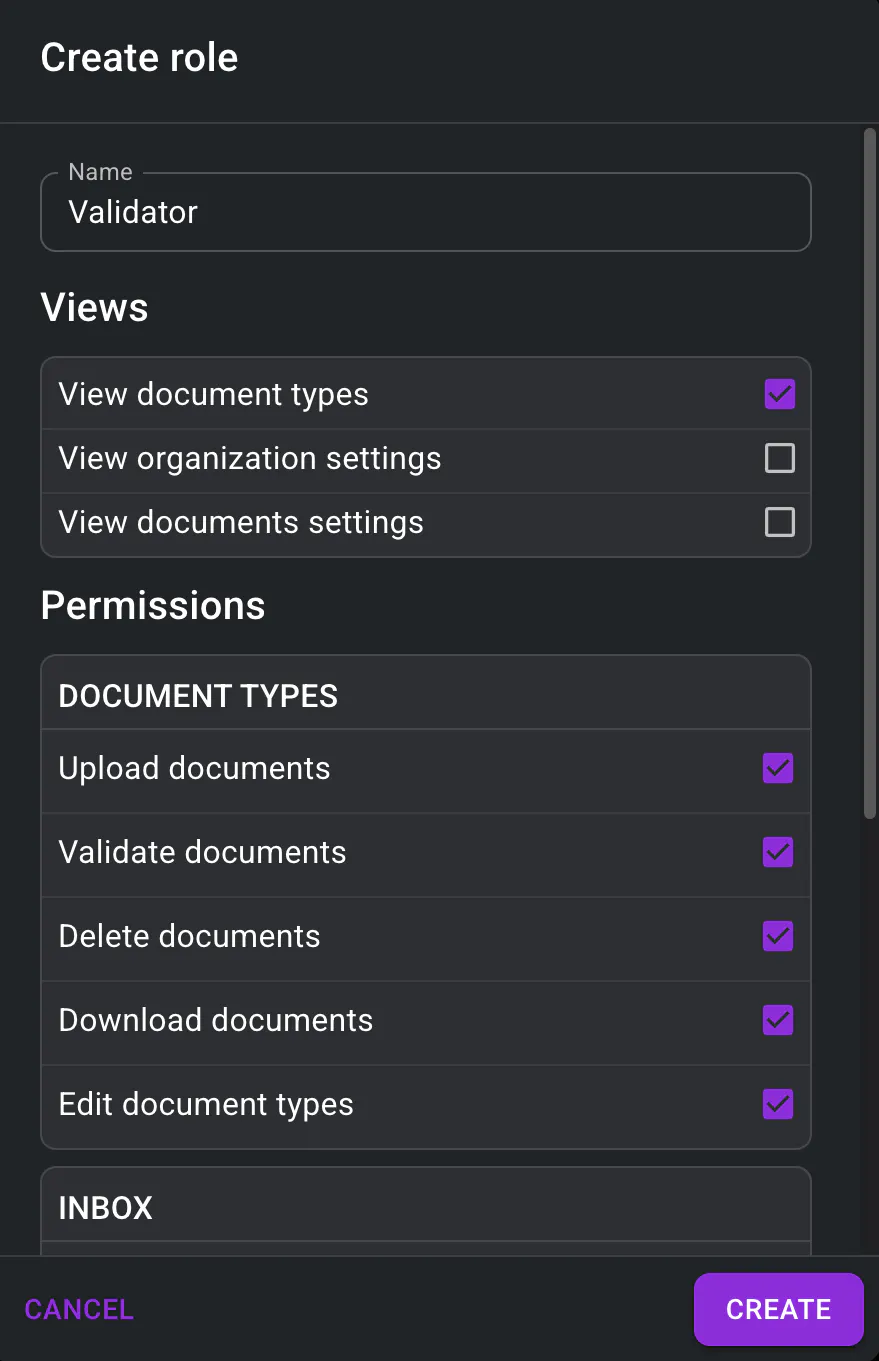
By default, each organization has an Admin role with access to all permissions. In addition, you can create your own roles and assign them to users based on their responsibilities.
This makes it easier to control who can view settings, manage document types, upload documents, validate documents, or perform other actions in Skwiz.
Document locking
Skwiz now shows when a document is being worked on by someone else.
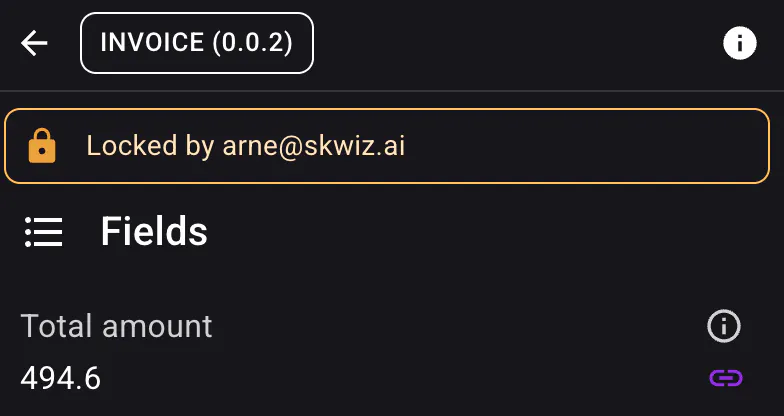
When a document is locked, users can immediately see who is currently editing it. This helps avoid overwriting each other’s changes and reduces duplicate work during review.
A document is automatically unlocked as soon as the user leaves it or after a period of inactivity.
A clearer Inbox flow
We’ve also updated the Inbox to better match the way documents move through Skwiz.
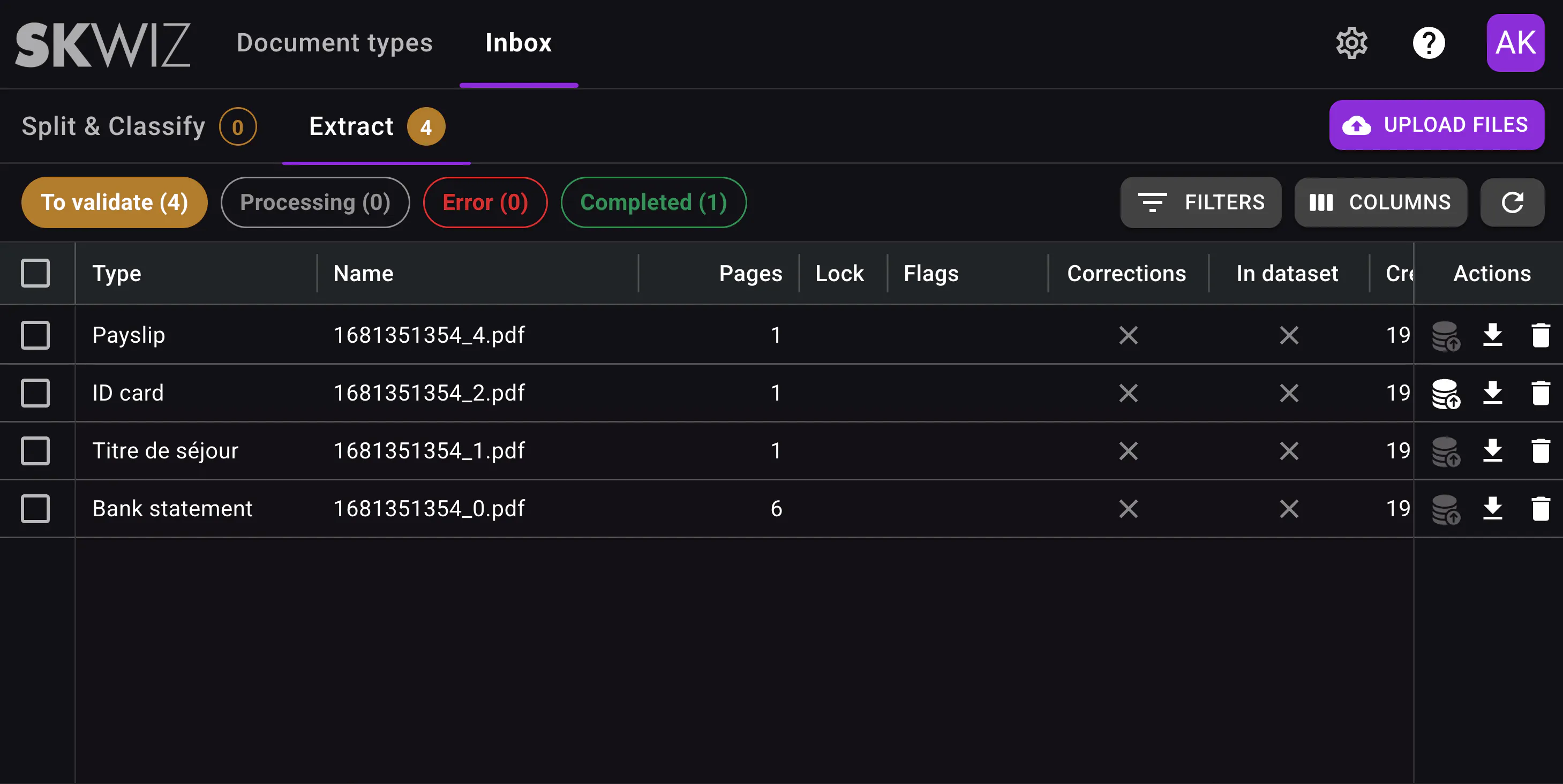
Instead of mixing splitting and classification documents with extracted individual documents, the Inbox now separates these stages into a more logical flow. Users can also immediately see how many documents require validation, making it easier to focus on the work to be done.
04 Mar 2026
Recap
It’s been a while since our last product update, and a lot has changed in Skwiz.
Over the past months, we’ve focused on one main goal: making document processing easier for business users to configure, review and improve.
Here’s a recap of what we’ve rolled out (more details below):
Easier setup and configuration:
Redesigned web app
Automatic document type setup from just a few example documents
Smarter document understanding:
Improved classification with layout matching
Extraction of Excel files
Faster review and continuous learning:
Continuous learning from corrected documents
Smart apply for faster table corrections
Validation rules for added control
Redesigned web app
We redesigned the web application to make it easier for business users to configure and manage document types.
To simplify the setup experience, we centralized configuration in one place and merged the former Model Studio and document type setup into a single document type configuration flow.
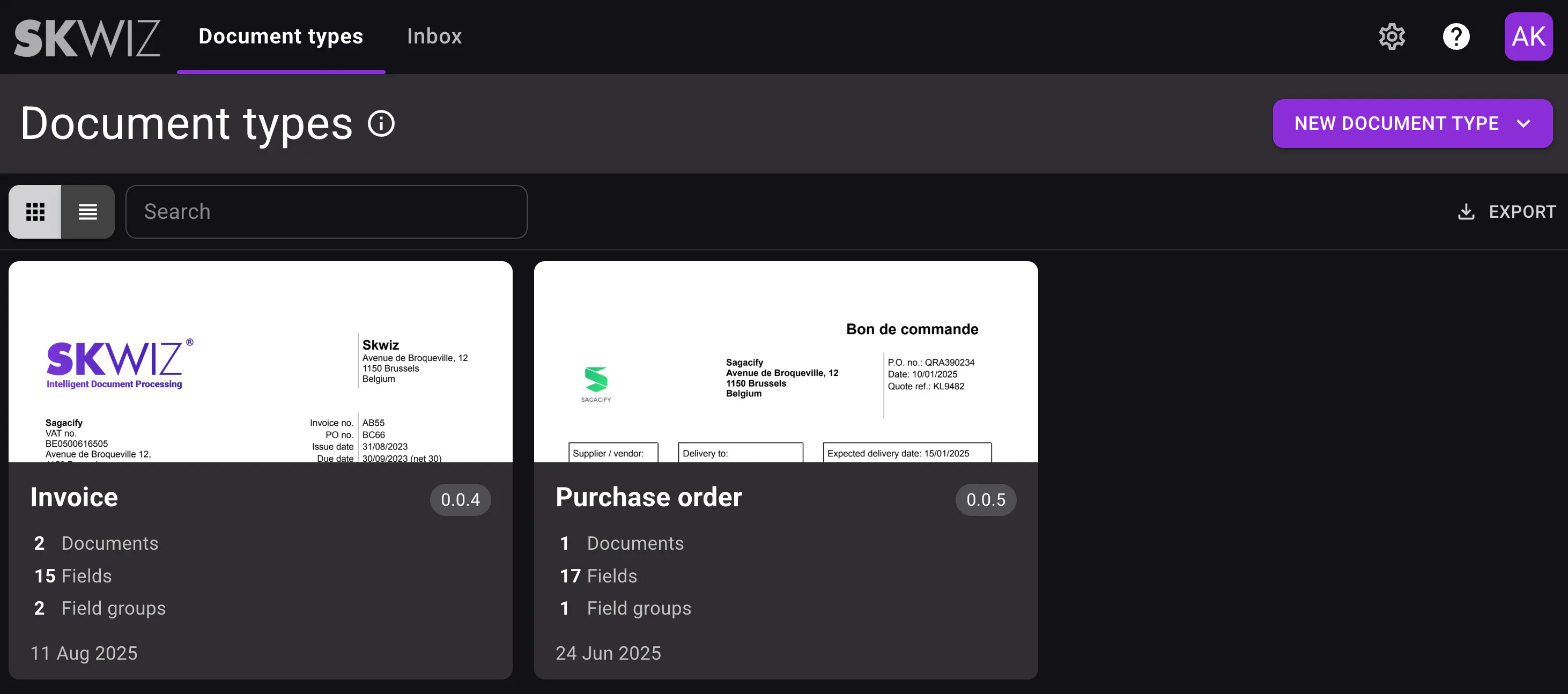
You can now also update your document type configuration by adding or modifying fields. Documents that were extracted or validated with a previous configuration are flagged so users can clearly review what changed.
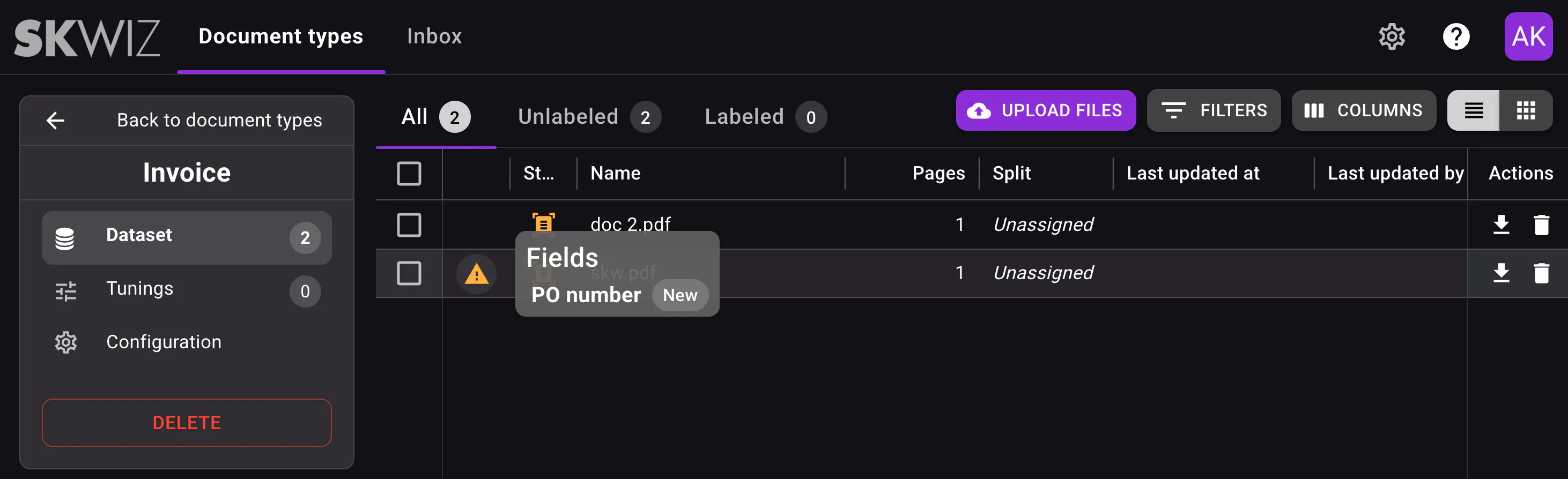
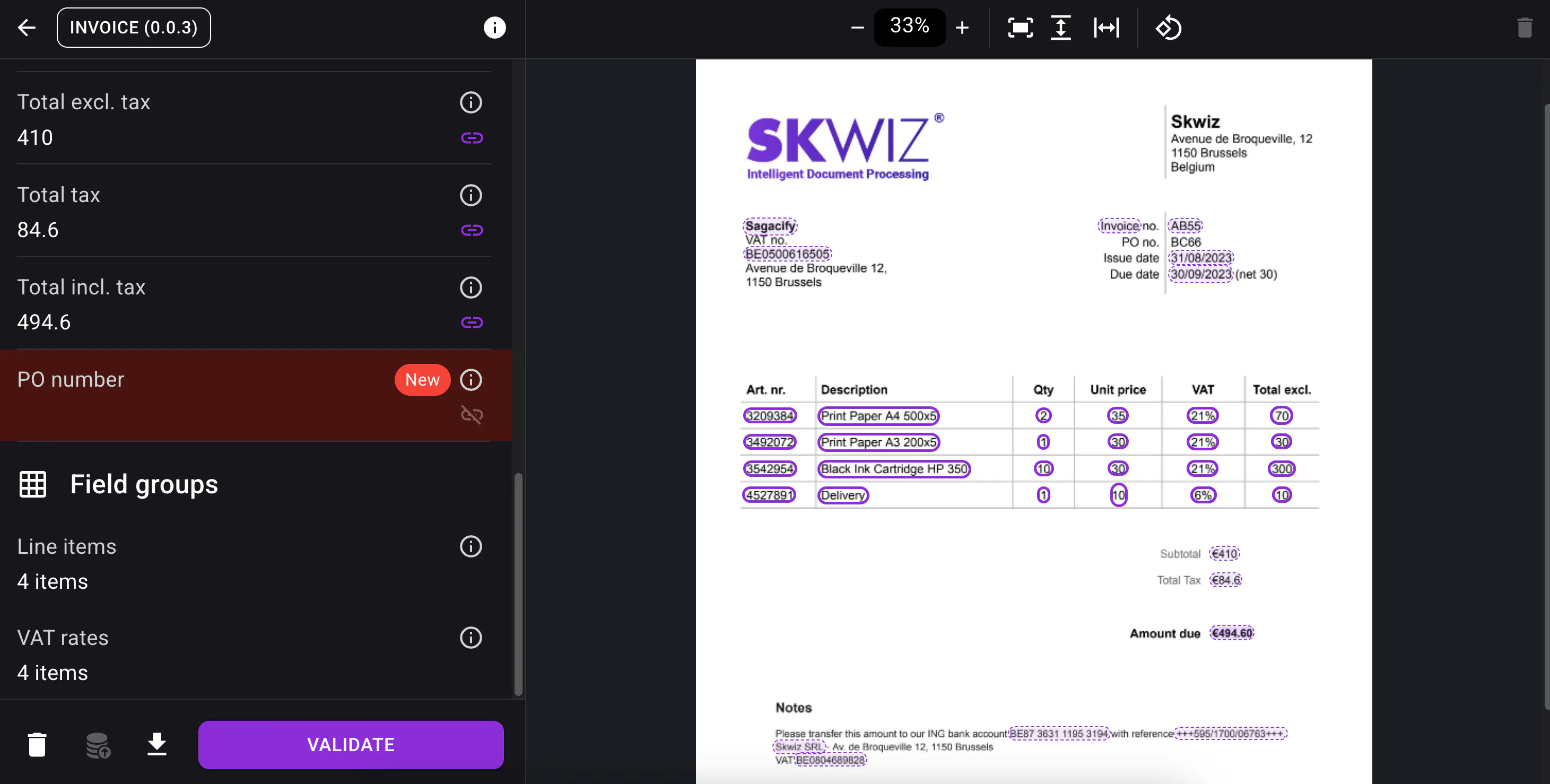
Automatic document type setup
You can now upload up to 3 example documents and let Skwiz automatically propose the fields and field groups to extract, including their data types.
This makes it much faster to get started with a new document type and reduces the amount of manual setup required.
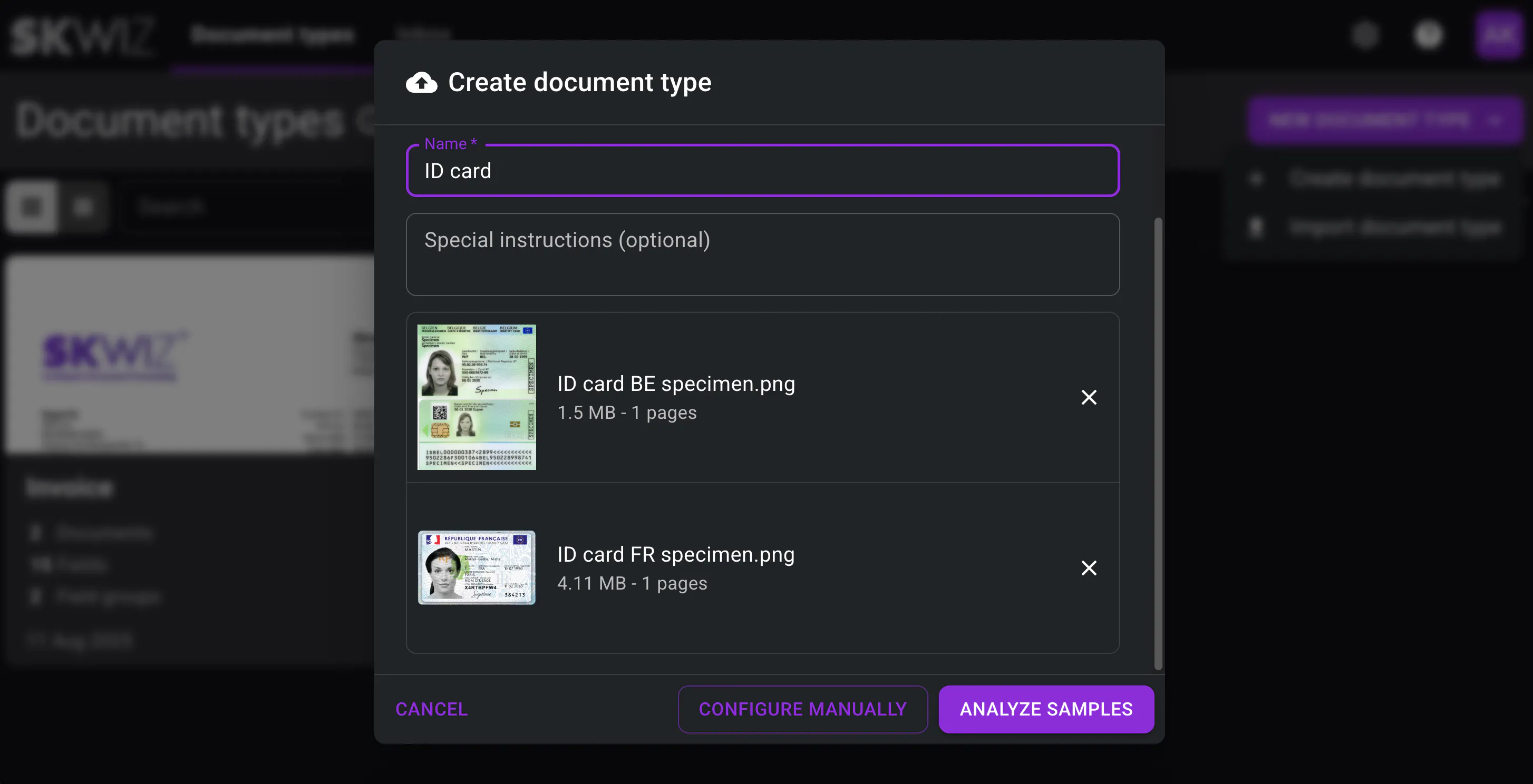
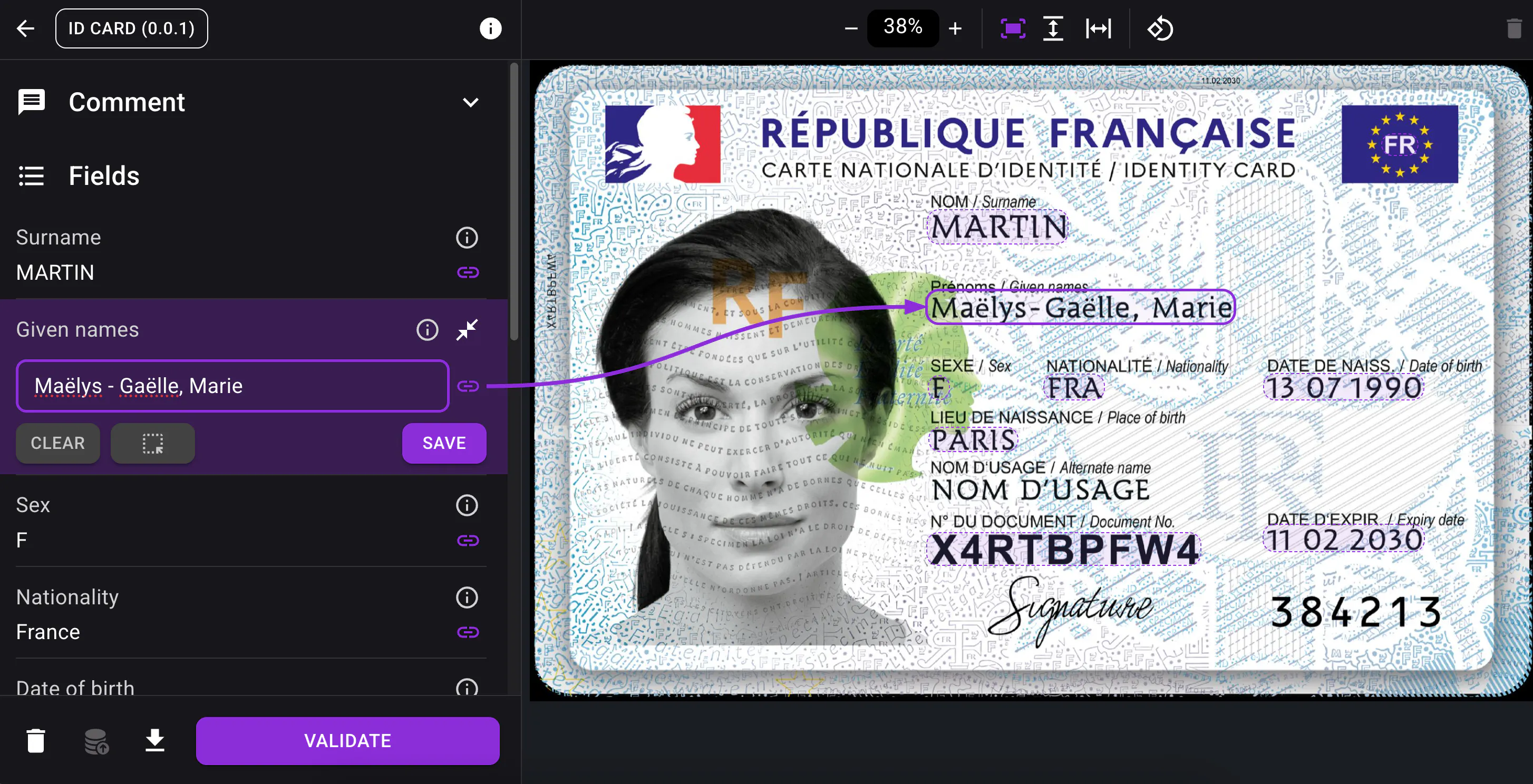
The fields configuration can be refined at any time:
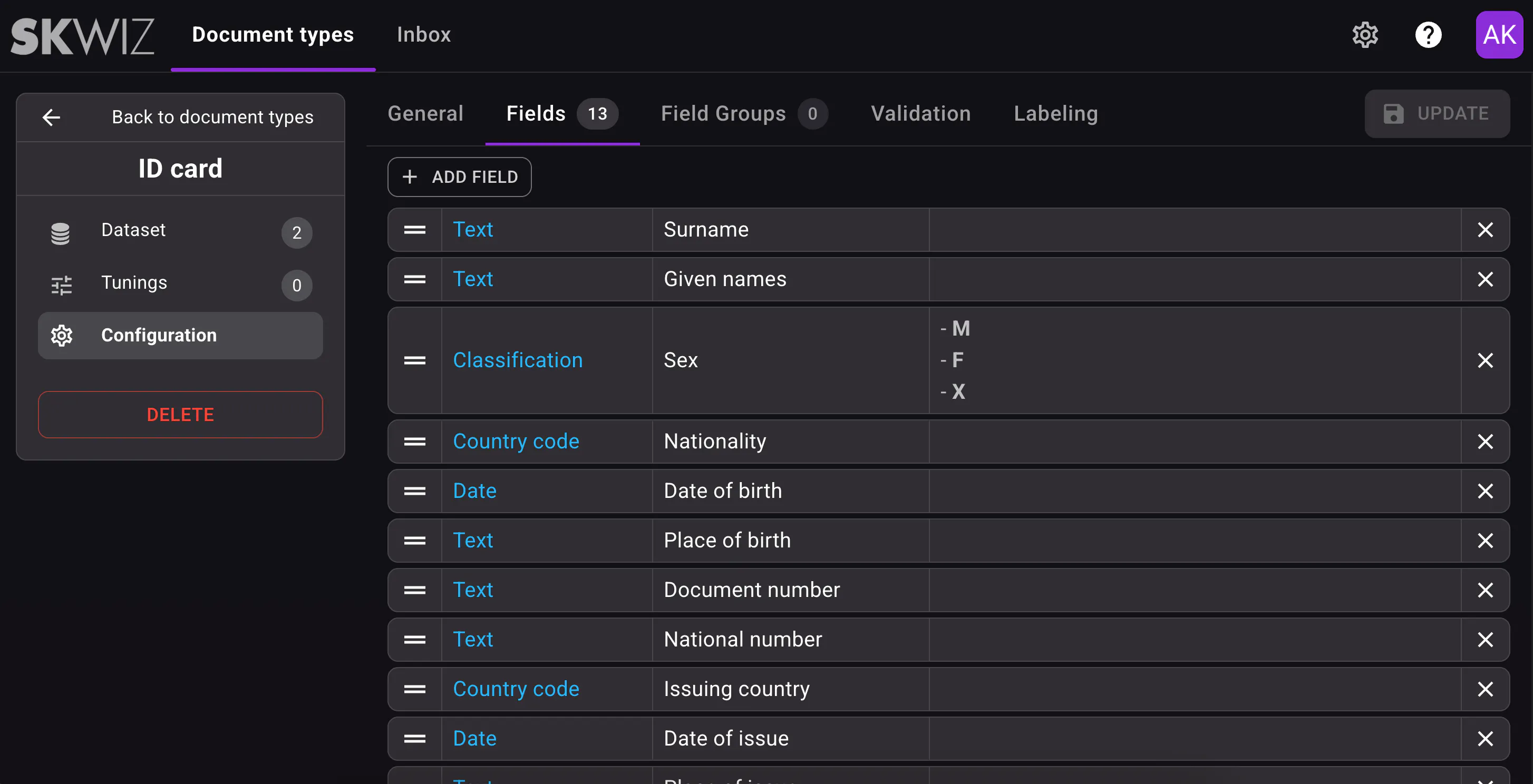
Classification through layout matching
We further improved document type classification by adding layout matching.
With layout matching enabled, Skwiz checks whether an incoming document is similar to documents already present in the datasets of your configured document types, both visually and in terms of overall content and structure. If a strong match is found, that document type is selected.
Classification is now performed in 3 consecutive steps:
- Keyword matching (if keywords are configured): if there is a match, classification stops here. We recommend using keyword matching only when a document type contains highly specific wording that is unlikely to appear in other document types.
- Layout matching (if enabled): if a similar document is found, classification stops here.
- Decision by AI: if no keyword or layout match is found, Skwiz interprets the content of the document and matches it to a document type based on the document type names and descriptions.
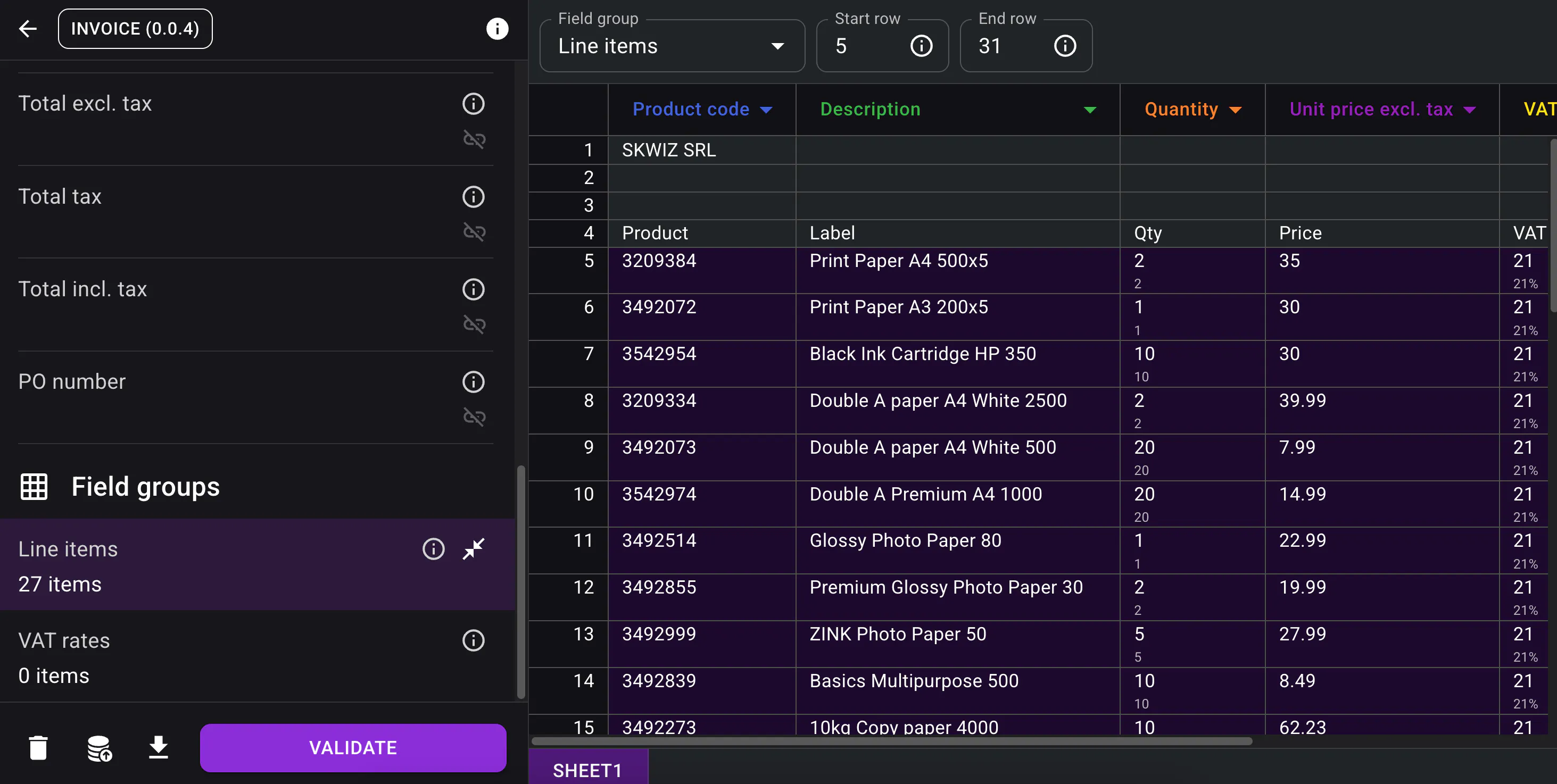
Extraction of Excel files
Skwiz now also supports extraction from Excel files for field groups.
The model automatically determines which columns correspond to the configured fields in your field groups and identifies which rows should be ignored. See in the below an example of an excel file where each column is identified, and lines 1 to 4 are correctly excluded.
Continuous learning
Continuous learning makes it possible to improve extraction performance automatically based on user corrections.
You can configure how much manual review is required before those corrections are used:
Learn automatically: corrections immediately improve the model. Recommended only for teams with very high confidence in the quality of their corrections.
Learn with review: corrections are saved to the dataset, but not applied immediately. A user must explicitly review and confirm them in the dataset before they are used. This generally leads to the best label quality, but can slow down learning.
Manual: corrected documents can only be manually imported to the dataset.
Off
We generally recommend starting with Learn with review to ensure labels are validated twice before they affect extraction quality.
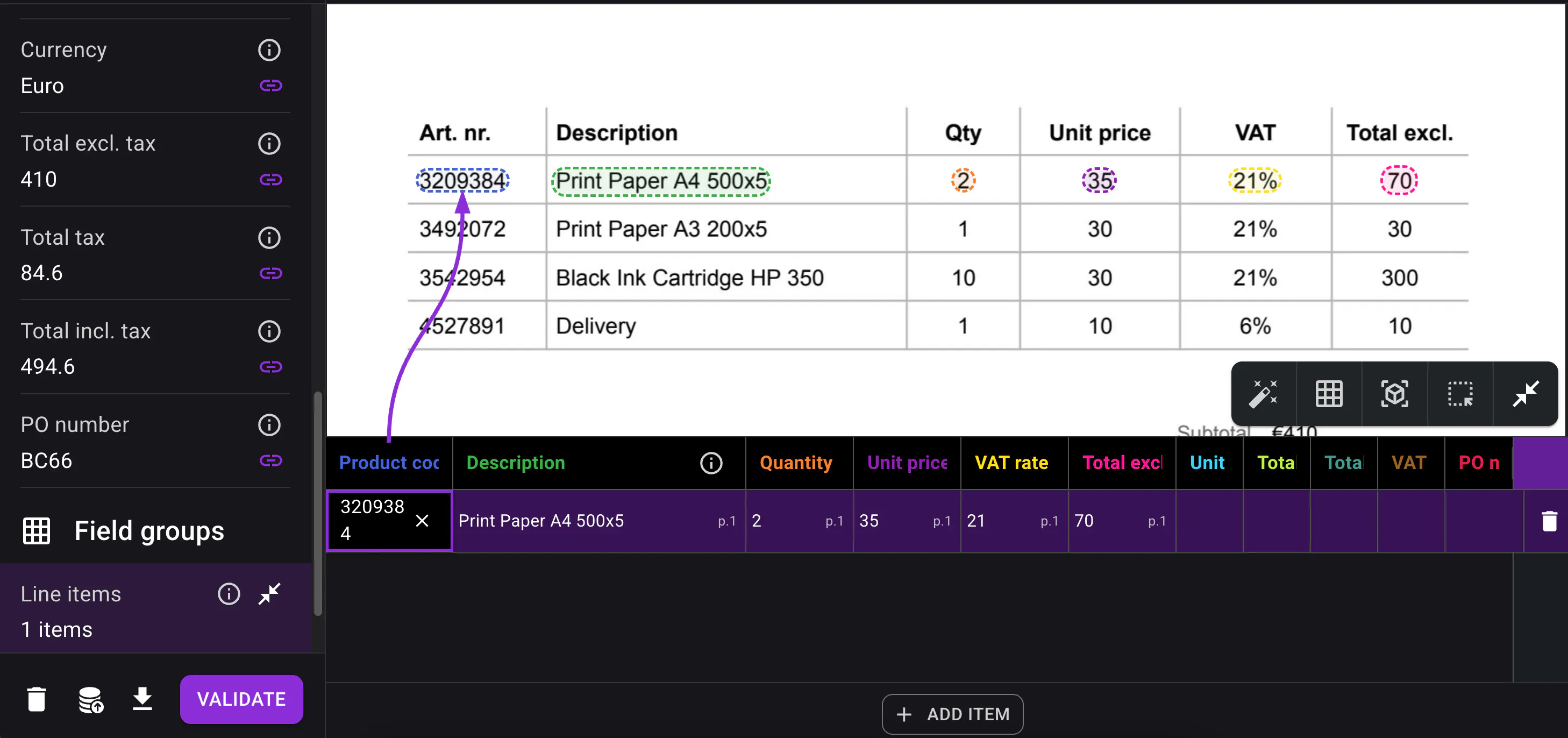
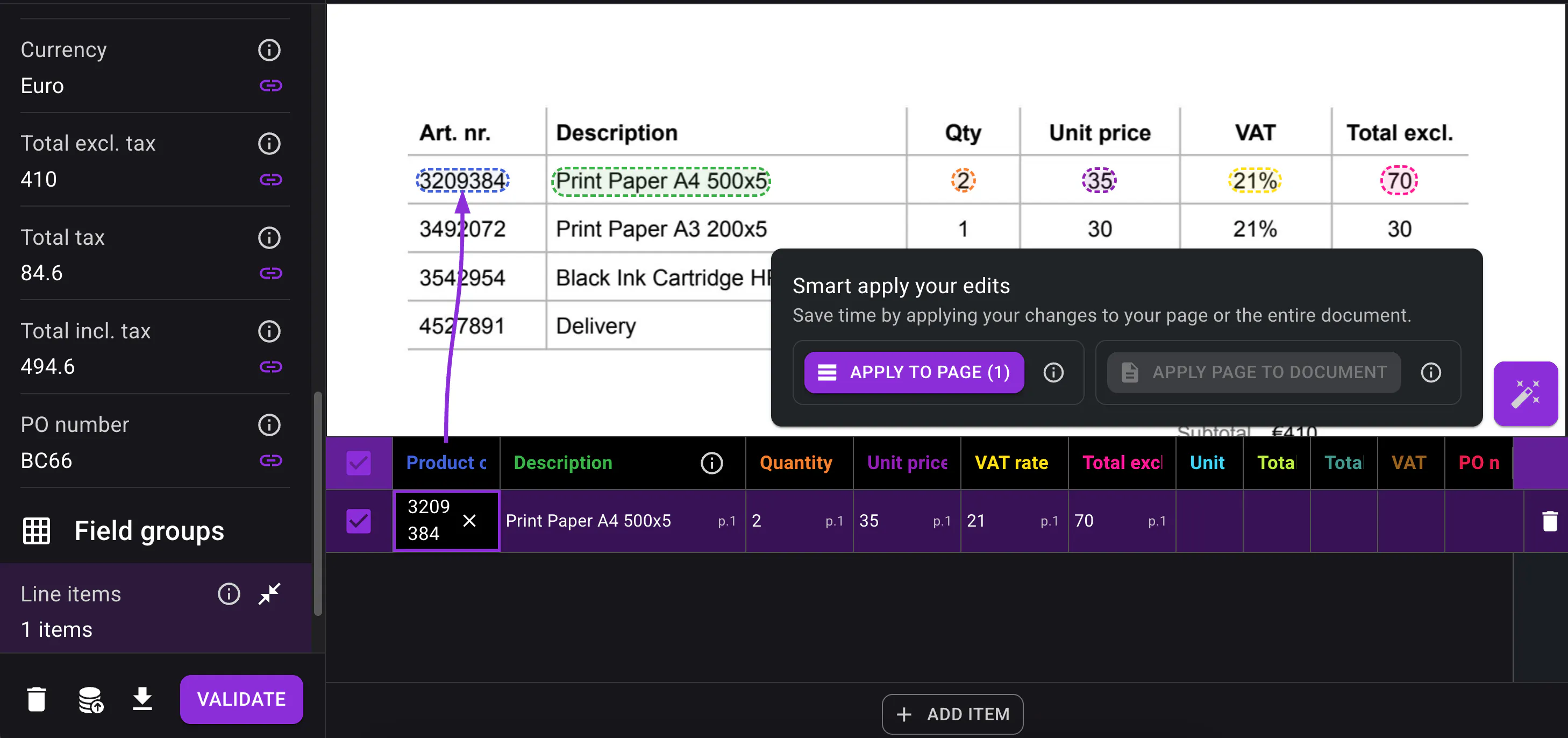
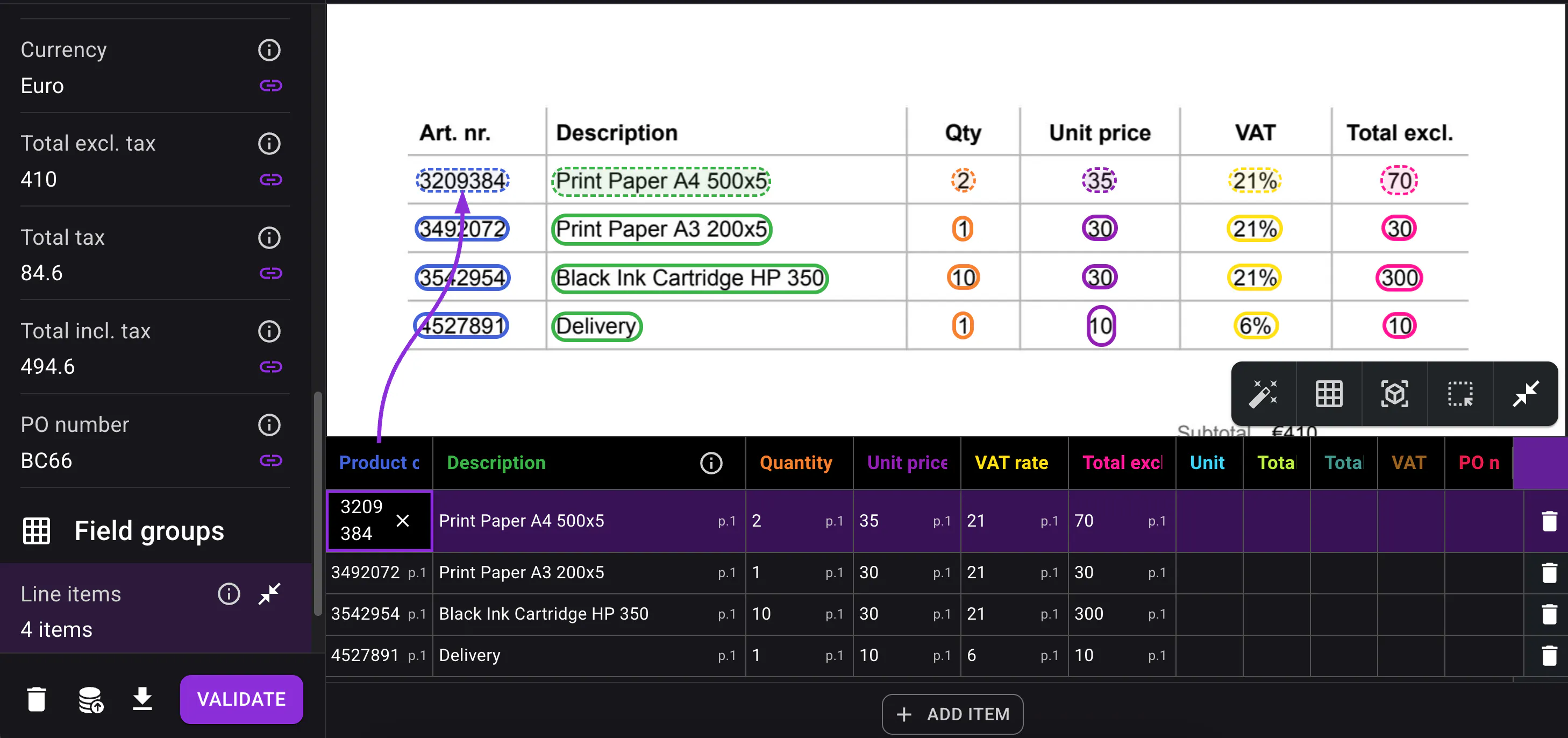
Smart apply for faster table corrections
Correcting tables is now much faster with Smart apply.
Instead of manually updating each line one by one, users can correct a single line and apply that correction to the rest of the table where relevant.
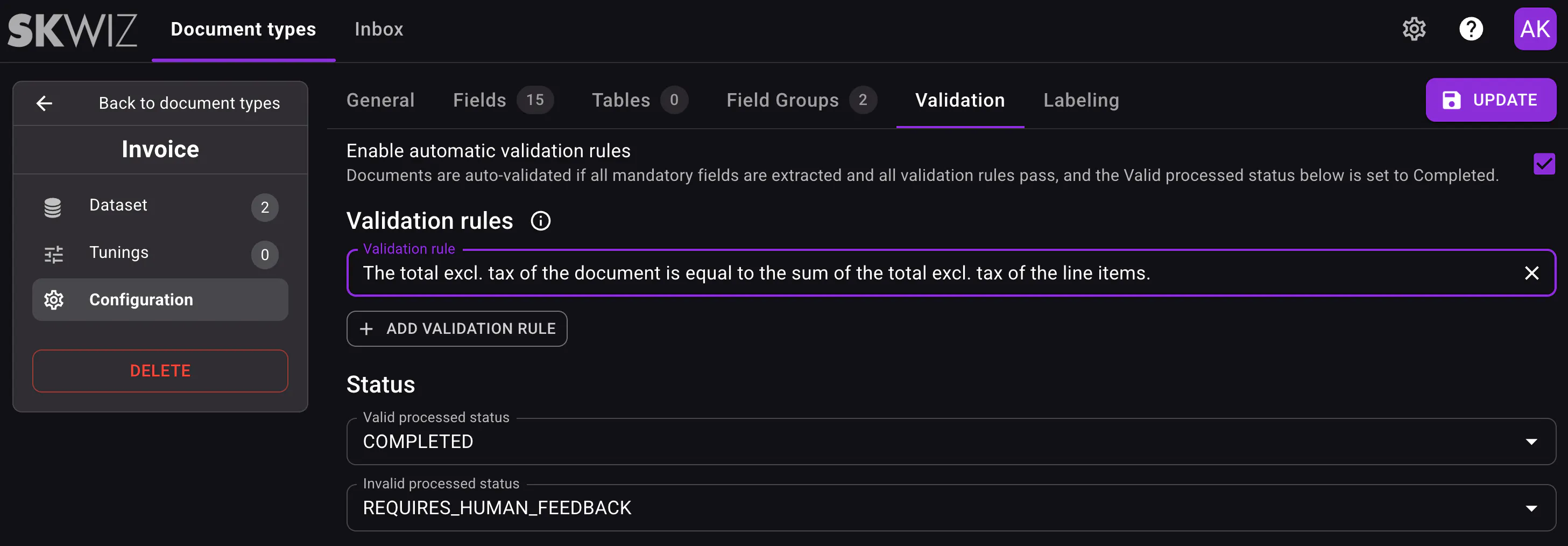
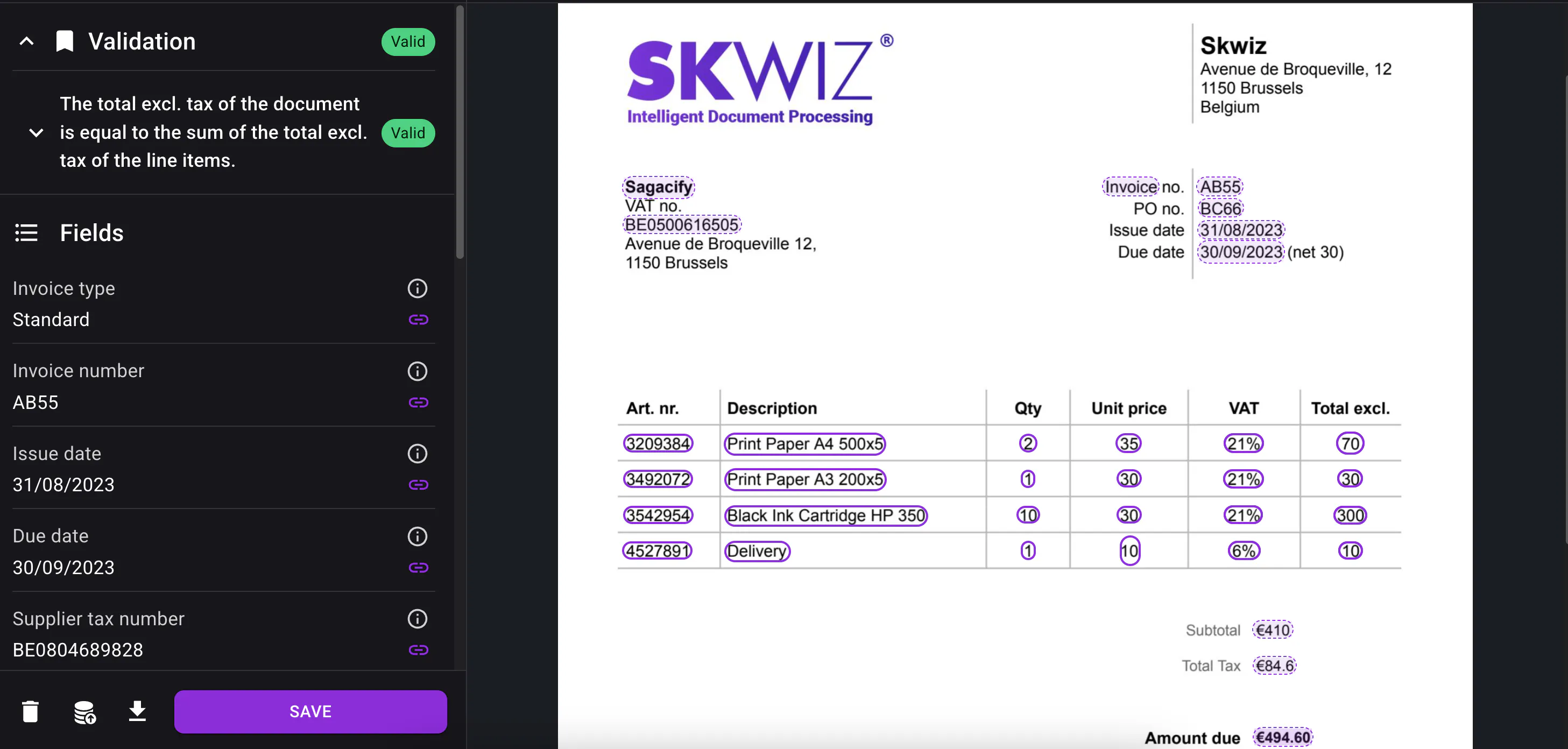
Validation rules for added control
You can now configure validation rules to add another layer of control to document review workflows. These rules are validated by a generative AI model.
Validation rules make it easier to check whether extracted data meets the expected business logic and help users focus their attention where it is most needed. Documents can be automatically completed or flagged for manual review if one of the validation rules is not met based on the configured valid and invalid processed statuses.
Other changes
Invoice to UBL: upload your invoice and receive a Peppol-compliant e-invoice in UBL format. This can help support outbound e-invoicing compliance.
Authentication through OAuth 2.0
07 May 2025
Improved complex table extraction
We've optimized our generative AI models to extract data from even the most complex table structures.
The models excel at processing documents like dangerous goods declarations (see illustration), where companies use widely varying table layouts, and naming conventions. The system adapts to varied table structures including merged cells, nested headers, and custom field labels while maintaining extraction accuracy. Whether tables span multiple pages, use unconventional layouts, or mix structured data with free-form text, the models extract complete information reliably.
Clients can fine-tune these models on their specific documents, teaching the system to recognize their unique table structures and terminology. This creates highly specialized extractors that understand your exact document formats and business logic.

24 Mar 2025
Fine-tuning generative AI for extraction
You can now fine-tune generative AI models specifically for your document types, delivering strongly improved extraction accuracy with minimal training data.
This isn't just an incremental update, it's a next step for document understanding. Here’s what it means for you:
Up to 10x less training data: where you previously needed hundreds of examples, you can now achieve superior results with as few as 10-20 documents per type, allowing you to go live in hours, not weeks.
Visual understanding: the new models don't just read; they see the whole document. This visual understanding allows them to interpret information that was previously out of reach. The AI can now recognize logos to identify a supplier, understand technical drawings, or use the placement of a signature to validate a form. It comprehends the document's structure visually, just like a human would.
Deep contextual awareness: go beyond simple key-value extraction. They understand the document context fully, allowing them to make logical inferences about data relationships in e.g. complex table structures while maintaining accuracy.
Superior handwriting recognition: we've made a big leap in processing handwritten text. The new models are significantly more adept at deciphering even messy, cursive, or rushed handwriting. This unlocks reliable automation for a whole new class of documents, like handwritten intake forms, field service reports, and annotated logs.
21 Jan 2025
Smarter PDF splitting with generative AI
We’ve rebuilt our PDF splitter to handle any document type intelligently with an accuracy above 95%. This update is now live for all users. Drop your next multi-document PDF into Skwiz and see the new splitter in action.
Processing large PDFs can be a chore, especially when they contain a mix of different documents like cover sheets, work orders, or certificates. Manually splitting these files is time-consuming and prone to error. Today, we’re launching a complete overhaul of our document splitting feature, powered by generative AI to make this process effortless.
Our new splitting engine uses a generative AI model that understands documents on a deeper level. The model analyzes the entire context of your PDF, including document identifiers (like form or invoice numbers), page numbering, visual layout, and textual content to determine where one document ends and the next begins. This allows Skwiz to accurately separate any type of document, even when they're mixed together in a single file.
We've also redesigned the validation interface. Skwiz now visually groups the separated documents, stacking them in the side panel. This intuitive layout allows you to quickly scroll through the proposed splits and see the documents as distinct units.

17 Nov 2024
Handling 10,000+ page PDFs
We've reworked our technical architecture to handle massive PDFs.
Our new infrastructure can process enormous documents, including 10,000+ page PDFs that some of our clients upload to Skwiz for splitting and extraction. The system automatically scales resources based on document size, ensuring consistent performance.
This architectural upgrade eliminates previous size constraints and processing timeouts. Whether you're handling large technical document collections, comprehensive financial reports, or bulk scanned archives, Skwiz can now process them reliably.
Available now through the Skwiz API with no changes required to your existing workflows.
11 Sep 2024
Single sign-on (SSO)
Skwiz now supports single sign-on for both Microsoft and Google accounts.
By integrating SSO, your team can access Skwiz securely with one set of credentials. Register or log in now with just one click and reduce your team’s risk of password-related breaches and phishing attacks.
18 Jan 2024
PDF splitting
You can now further automate your document workflows with our PDF splitting feature.
If you often end up with a single, long PDF after scanning multiple documents in one go, you can now let Skwiz take care of it. We can automatically separate these scans into individual documents to automate even more of your workflow.
Enable PDF splitting now via Live documents > Configure > Workflow > Analysis > Enable.
To use it in the web app, select Analysis > Split document(s) when uploading a PDF.
To use it through the API, use the Analysis routes to upload your PDF.

19 Oct 2023
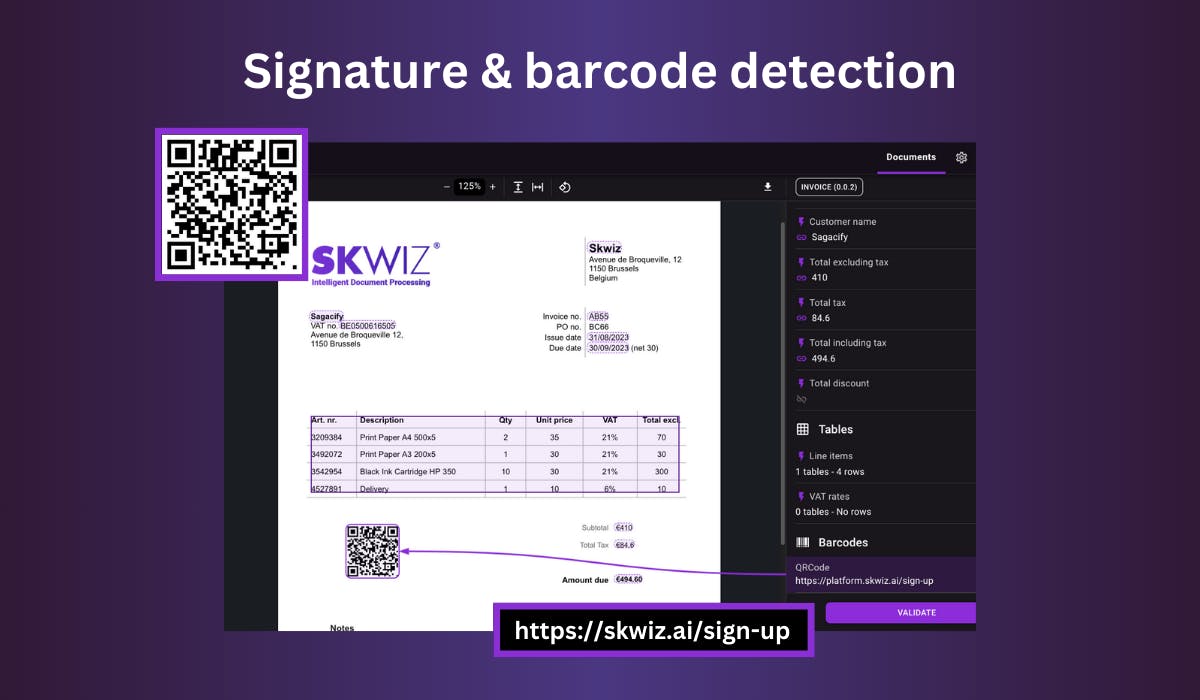
Signature + barcode detection
You can now detect all barcodes and signatures on your documents. Configure this new functionality with the click of a button in your Document type settings and Skwiz will locate the position of each object and extract the data associated with the barcodes.
We support the following barcode types:
Code39
Code128
DataBar
DataBarExpanded
DataMatrix
EAN8
EAN13
PDF417
QRCode
UPCA
UPCE
26 Sep 2023
Collaborative partner interface + Integratable UI
Collaborative partner interface
Our network of trusted partners plays a significant role in introducing and delivering Skwiz to our clients effectively. To streamline the management of various clients within Skwiz from a single account, we’ve added a collaborative partner interface. This allows you to facilitate client introductions and conduct demos showcasing value from day 1. In addition, you can invite colleagues and maintain a full overview and control, all from a single hub. We are confident that this feature will simplify your project management and further improve your experience in Skwiz.
Integratable UI
Seamlessly integrate part of the Skwiz UI into your own application, offering a read-only web view of the documents extracted by Skwiz. This integration enables quick, efficient document reviews and enhances your workflow without the hassle of having to switch between applications.
Other changes
Multi-user organizations: invite your colleagues to join your organization in Skwiz. Each user can be linked to multiple organizations.
Keyword classification: extension of document classification with LLM to allow classification based on keywords for full flexibility and cases where speed is important. We run keyword classification first if it is configured, followed by LLM classification if no match can be found with keywords.
Usage dashboard: get a live view of the pages processed by Skwiz. Usage is categorized in 2 groups. 'Extraction' lists the number of pages that were extracted and may have been classified. 'Classification only' lists the number of pages that were classified but not extracted. This is used to detect documents that do not require extraction because they are received via the same channel (e.g. a mailbox) as other documents and need to be filtered out. Classification only is generally priced lower than extraction.
10 Aug 2023
Optimized invoice & receipt models + Regular expressions
Optimized invoice & receipt models
We’re introducing our optimized invoice and receipt models, which are specific pre-trained models that use machine learning instead of large language models (LLMs). Trained on tens of thousands of example documents, these models have already demonstrated their effectiveness in improving data extraction for a number of our clients.
These optimized models can be used independently or in combination with LLMs, providing you with added flexibility. For example, you could configure Skwiz to use the optimized receipt model to extract essential data such as amounts, the issue date, supplier information and tables from your documents. LLM could then be used in addition to find a custom field (say the City) and categorize the content of the receipts in your specific classes, like “Restaurant”, “Hotel” or “Transport” in the field Category. Below you’ll find an example of such a configuration.
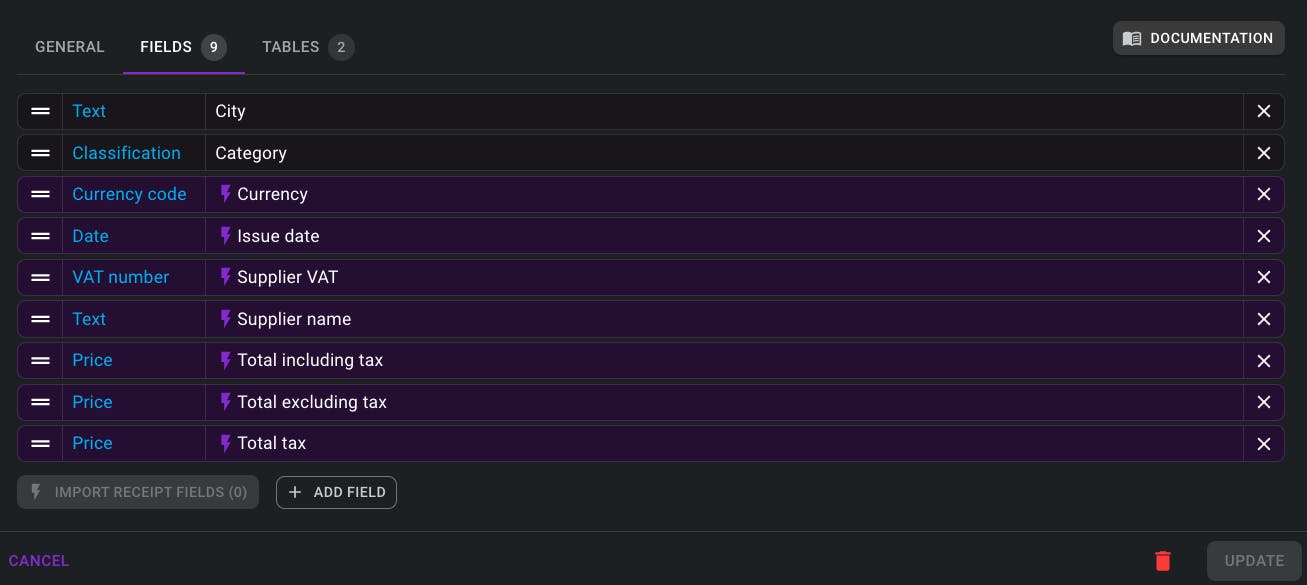
Regular expression
To further enhance the flexibility in data extraction, we’ve also added the possibility to define your own regular expressions (regex) and link these to your fields.
Even with the advanced capabilities of our optimized models and LLMs, the precision and efficiency of regex remains critical in the processing of documents. Particularly for pattern recognition in structured text, regex significantly outperforms models in instances where specific patterns can be identified and differentiated from surrounding text.
For example, if the Purchase Order number on your incoming invoices always consists of "PO" followed by 5 digits (e.g. “PO93438”), using regex (in this case `PO\d{5}`) will ensure flawless extraction from each document.
01 Aug 2023
Classification of documents, fields and line items
Introduction
You can now use classification, also known as categorisation, on multiple levels of your documents.
Document classification
Automatically identify the document type of any document you upload, for example:
“ID card” vs “Driver’s license” vs “Residence permit”
“Invoice” vs “Receipt”
“Invoice” vs “Other”
Field classification
Automatically categorize a document’s content, for example:
The expense category on a receipt: “Hotel” vs “Restaurant” vs “Transport”
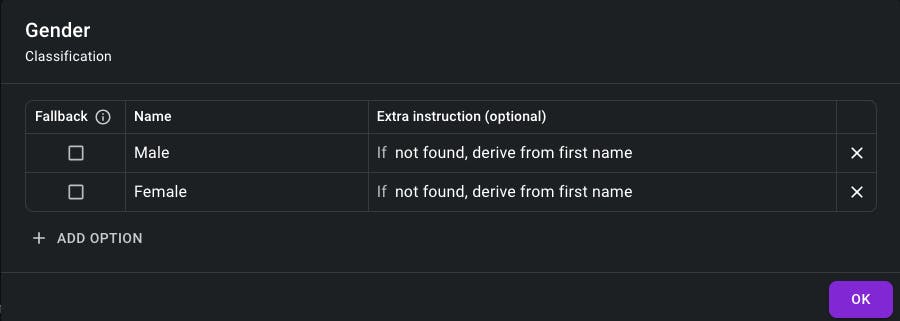
The gender on an ID card: “Male” vs “Female”
The type of a bank card: “Credit” vs “Debit”
Line item classification
Automatically categorize each line of a table, for example:
The category of each line on an invoice: “Goods” vs “Services”
The liability of each claim in a claims history letter: “Liable” vs “Not liable” vs “Shared liability” vs “Unknown”
Any of these classifiers can be set up within minutes.
Other changes
Improved table extraction, most notably for tables containing empty cells
Improved handling of dates: corrected the issue with certain dates not being parsed
Improved field type True/False: merged configuration and behavior with field classification
Added the document type key in the document definition modal
Document classification
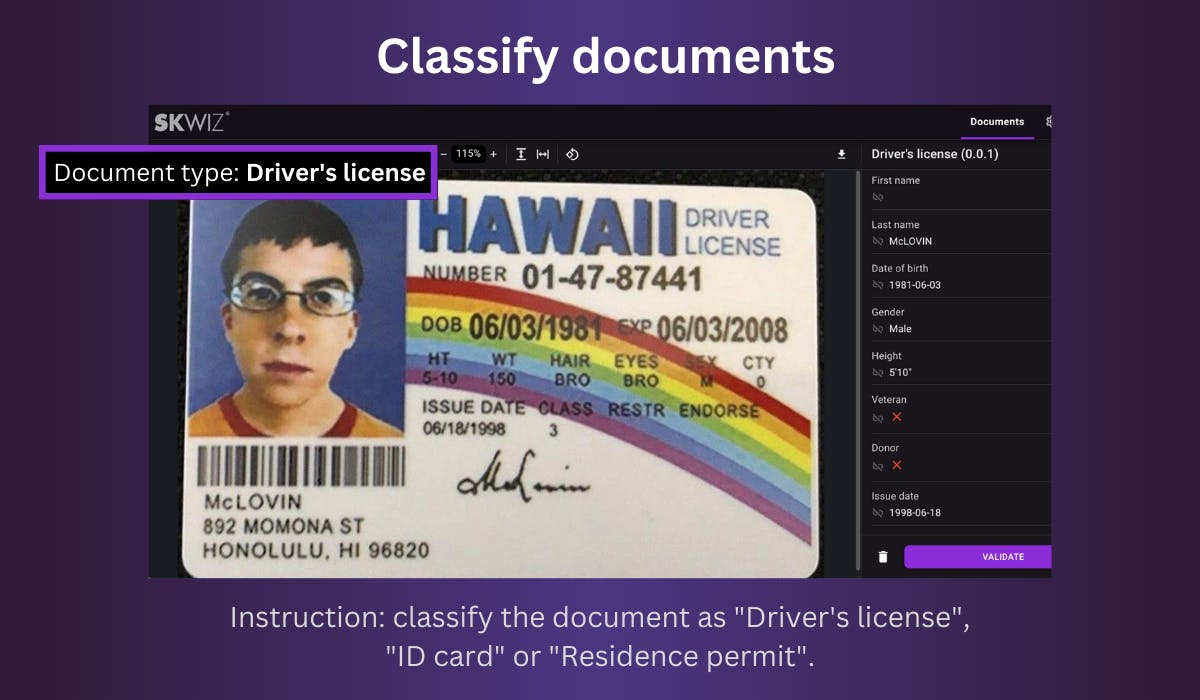
To automatically identify the document type of the documents you upload to Skwiz, you can build a classifier between 2 or more document types.
After defining what sets different document types apart, Skwiz can automatically distinguish one document type from another. Here is an example of descriptions that can be used to distinguish invoices from receipts:
"Invoice": contains information about both the seller and buyer, often contains a reference to invoice, facture, factuur, Rechnung, factura, etc. and typically contains bank information
"Receipt": shorter information which typically only contains information about the seller, and not about the buyer
You can set one of the options as fallback to assign this document type if no specific type can be determined.
It is possible to build multiple classifiers in case Skwiz is supporting multiple of your workflows.
Field and line item classification
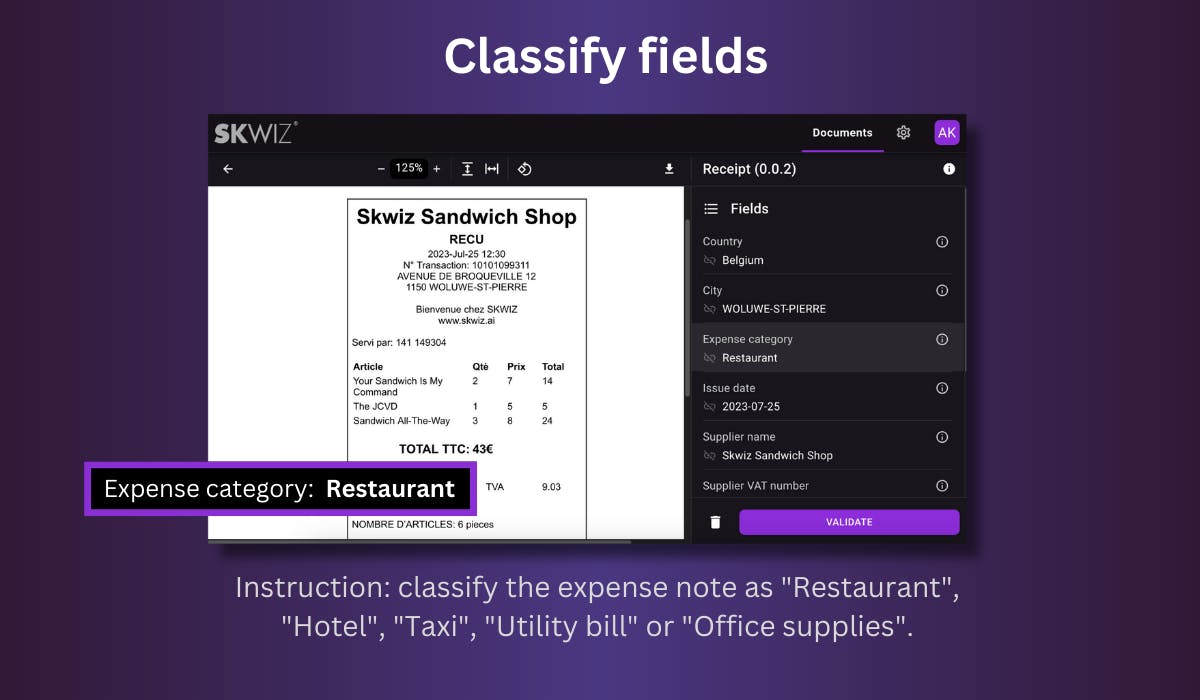
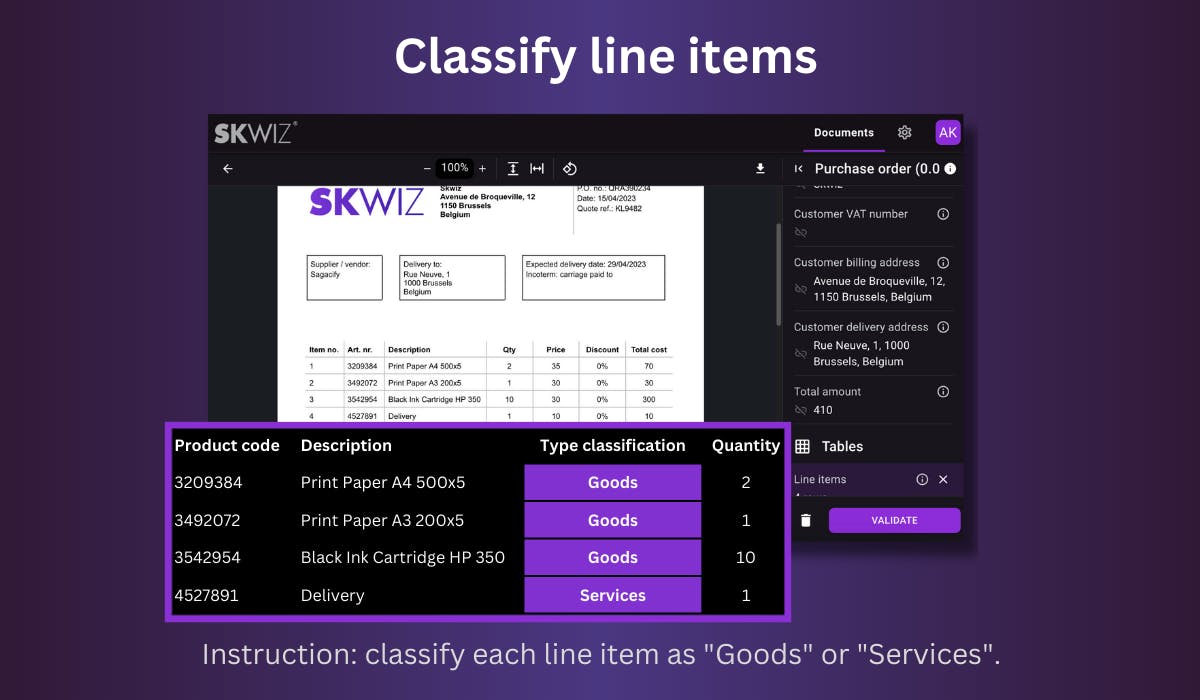
To classify a field or a line item, set its type to Classification and define 2 or more options. Optionally, extra instructions can be provided for more complex cases.
Set one of the options as fallback to return this value if no specific value can be found.
05 Jul 2023
Launch
Introduction
Skwiz enables you to extract data from any type of document with the use of large language models (LLMs) like ChatGPT. These LLMs have the capacity to understand and generate natural language, enabling very precise extractions and allowing simpler and more enjoyable ways to work with documents, in virtually any language. This further results in shorter and less costly setups in comparison to traditional rule-based or machine learning approaches as it mitigates the need for extensive training data and time-consuming manual labelling.
This first version of Skwiz aims to provide a radically simple flow to set up your document types autonomously within minutes, while still providing you with the flexibility to influence the quality of the extractions. We dedicated a great deal of attention to the extraction of tables, as their content is often critical and manually entering this data takes up much of the time of those who handle these documents.
In addition, we added a validation step and API to seamlessly fit Skwiz into your existing business workflows.
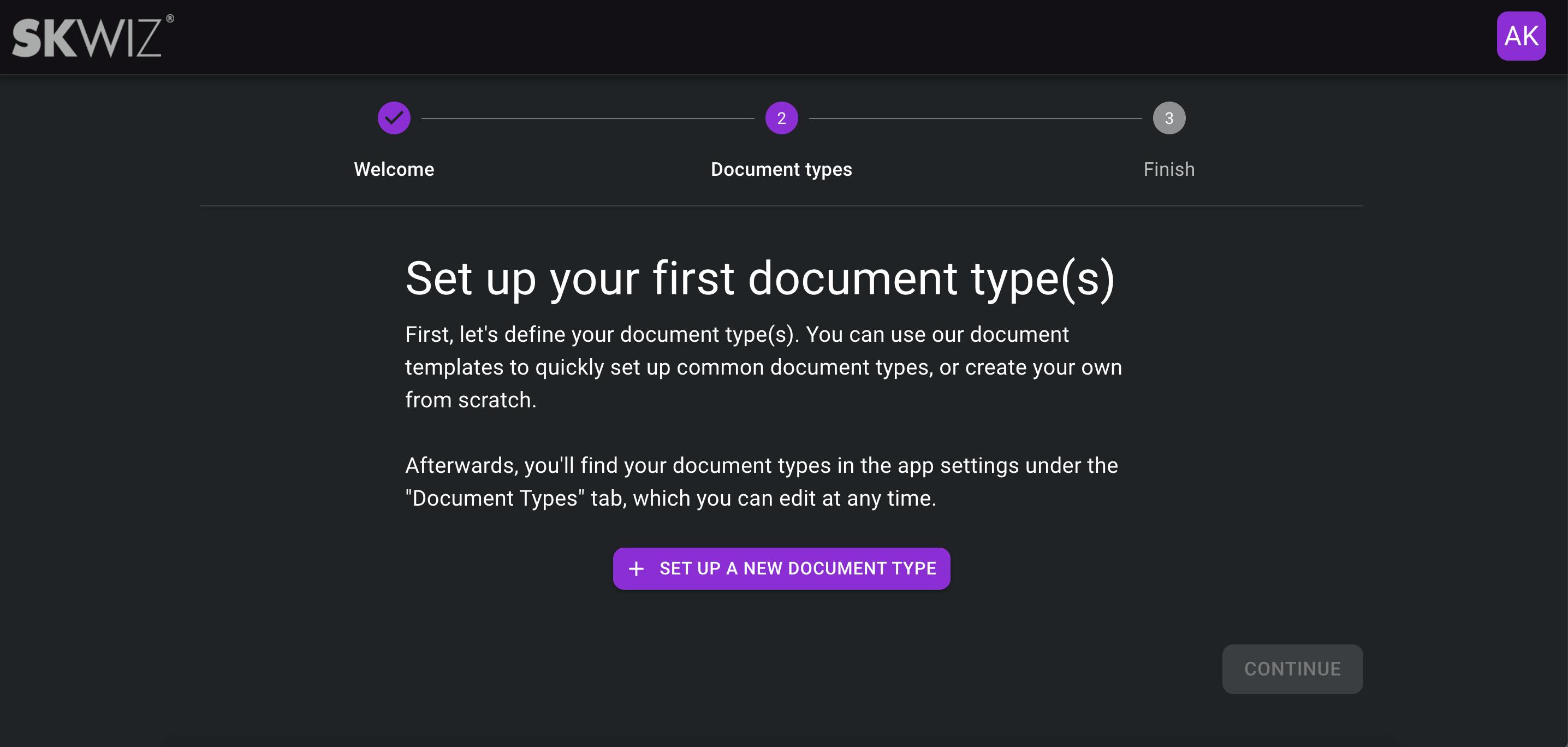
Onboarding flow
The onboarding flow will guide you, as a new user, to define your first document type with minimal guidance and will introduce you to the document templates.
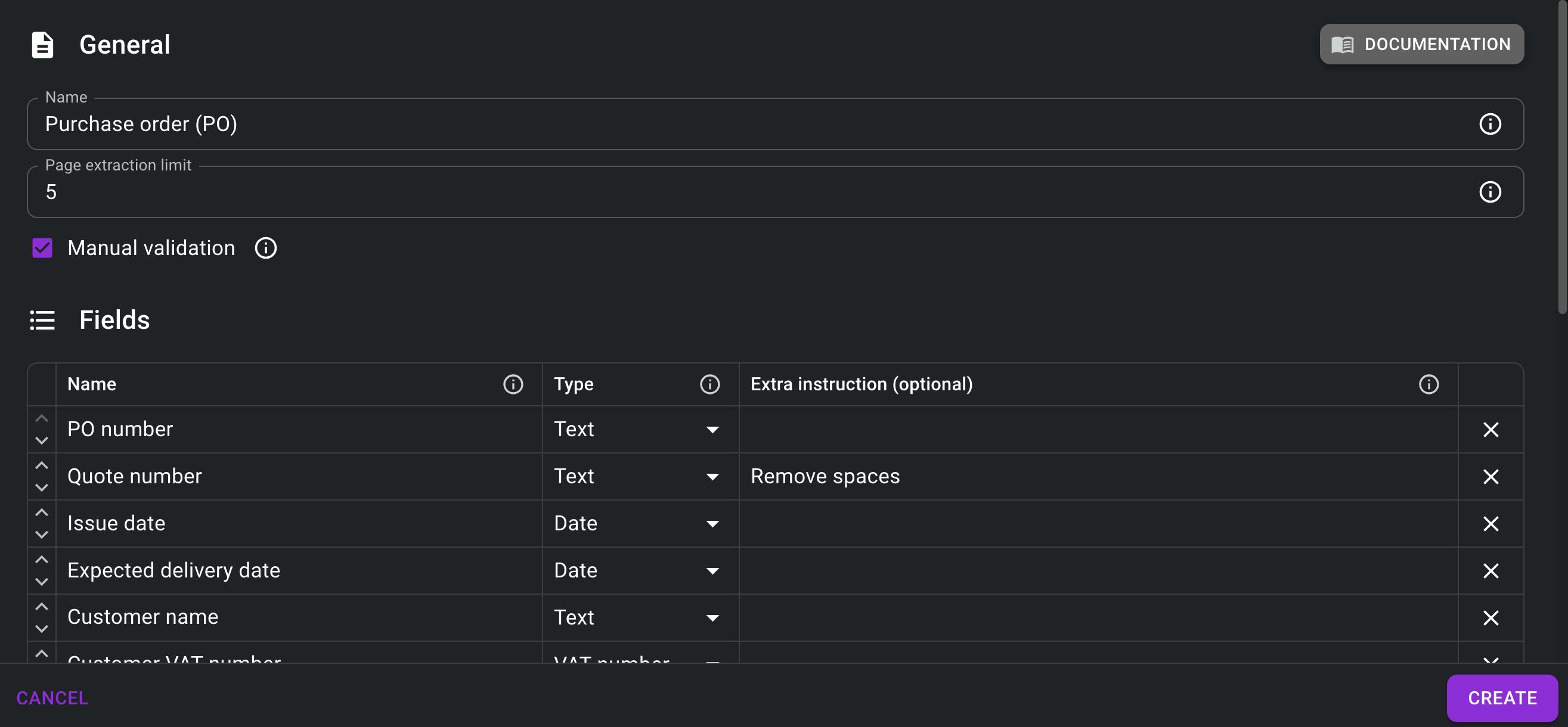
Document type definition
The core configuration in Skwiz: defining the document type, fields and extra instructions that will drive the extraction. You can define regular fields as well as fields that need to be extracted from line item tables. We’ve added tooltips and documentation to guide users in getting the most out of Skwiz.
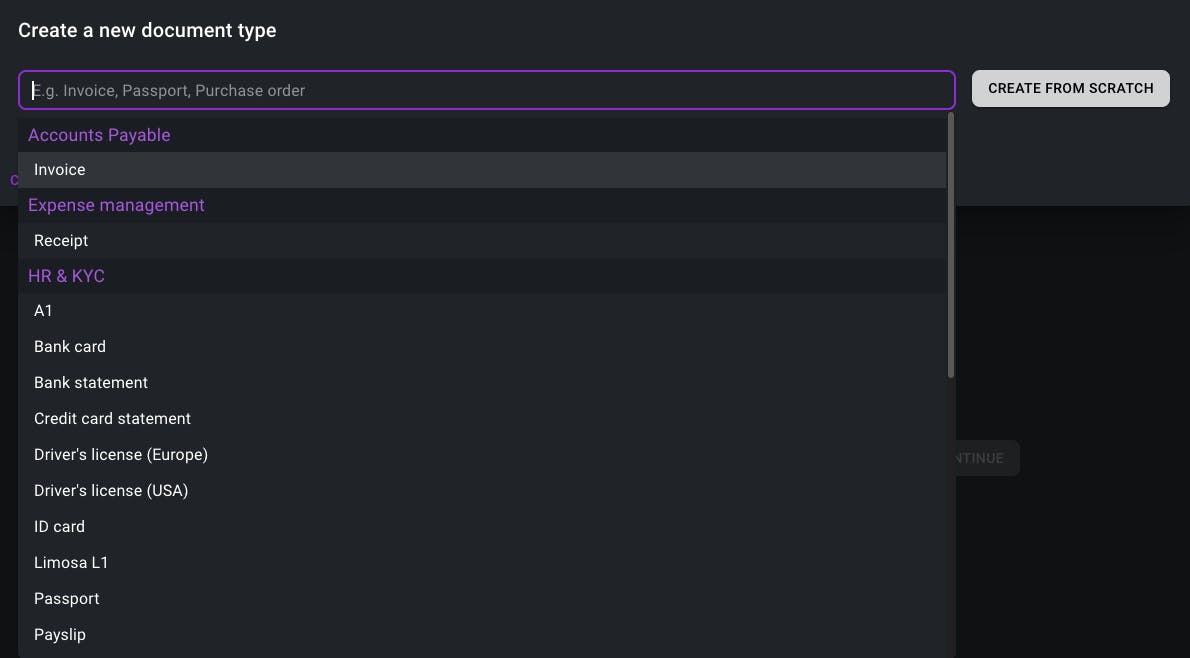
Document templates
Our document templates propose configurations for common document types like purchase orders, invoices or ID cards. These templates can be fully customized by adding or removing fields and writing instructions that better fit your specific documents.
Highly structured documents that always contain the same information like ID cards, passports or driver’s licenses can directly be used as is.
Alternatively, users can create their own document types from scratch when handling less common document types that are not yet included in the templates.
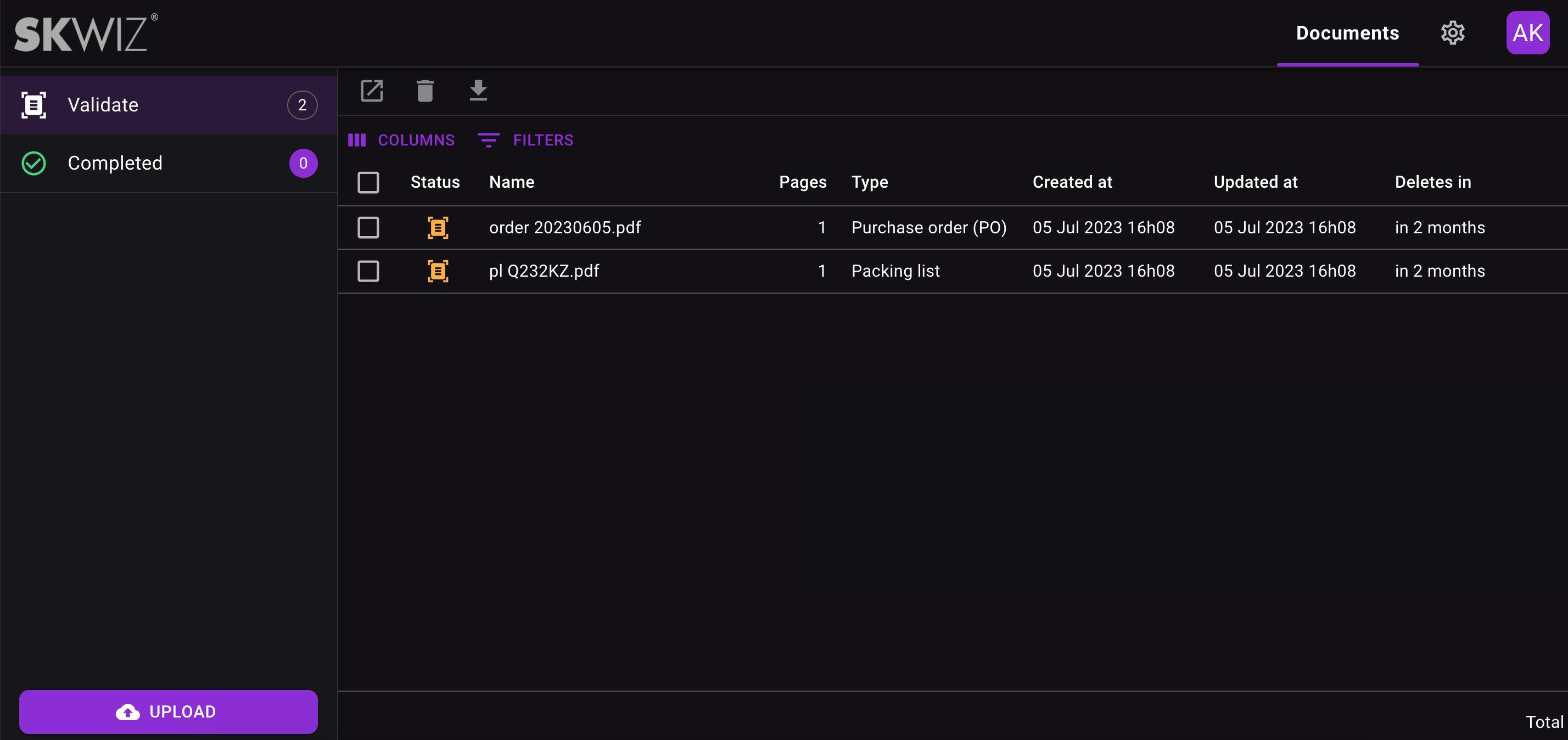
Document overview
The document overview allows you to upload documents by drag-and-drop and shows all documents per status. The “Validate” status includes all documents that have been extracted and require manual validation by a user. After validation, documents move to the “Completed” status.
You can configure it to skip the manual validation step in the document type settings, making documents directly transition to the “Completed” status after extraction.
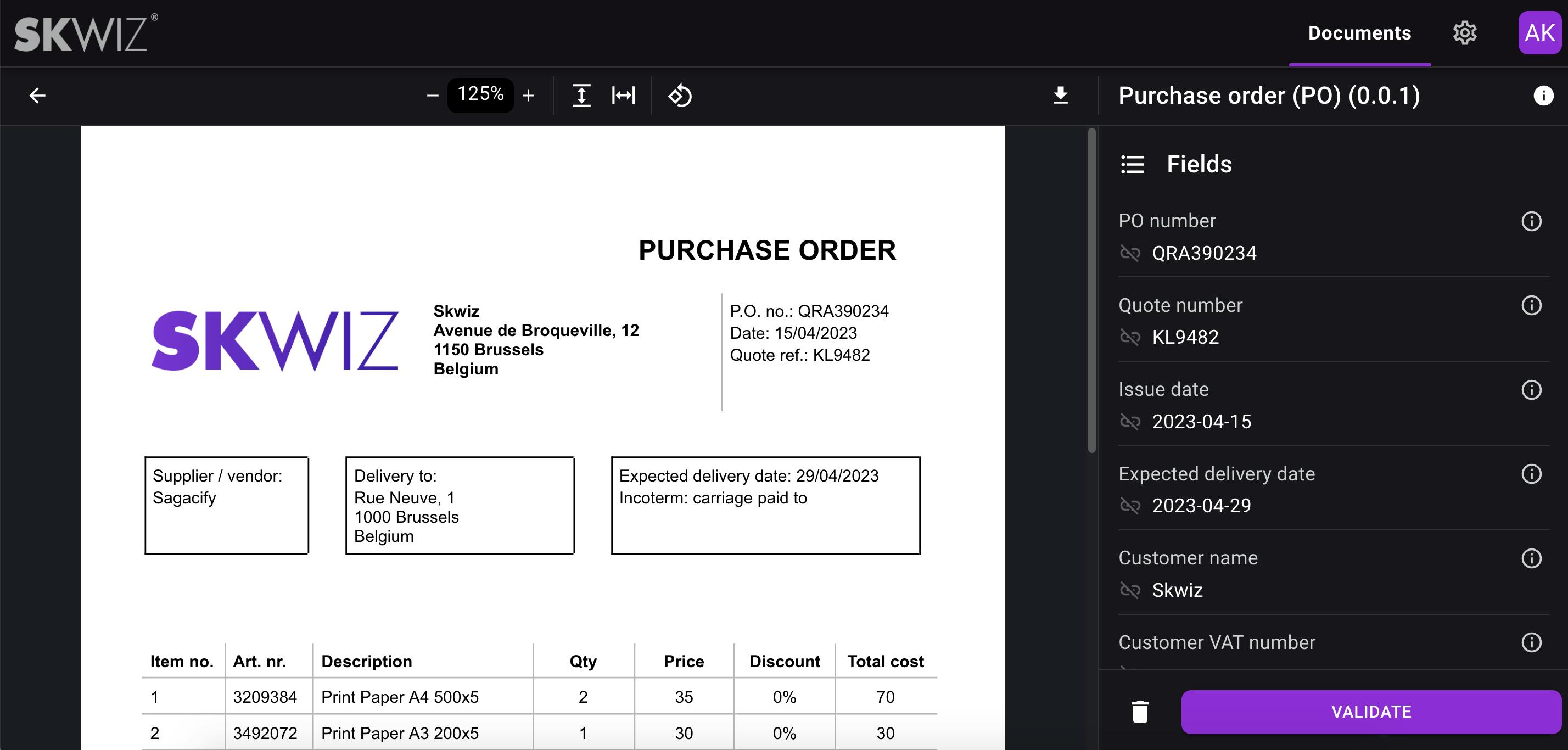
Document validation
You can modify the values of extracted fields as well as data extracted from tables by selecting text directly on the document, avoiding the need for typing. You can also add or remove rows in the table output grid. Validating a document will put it in status “Completed”.
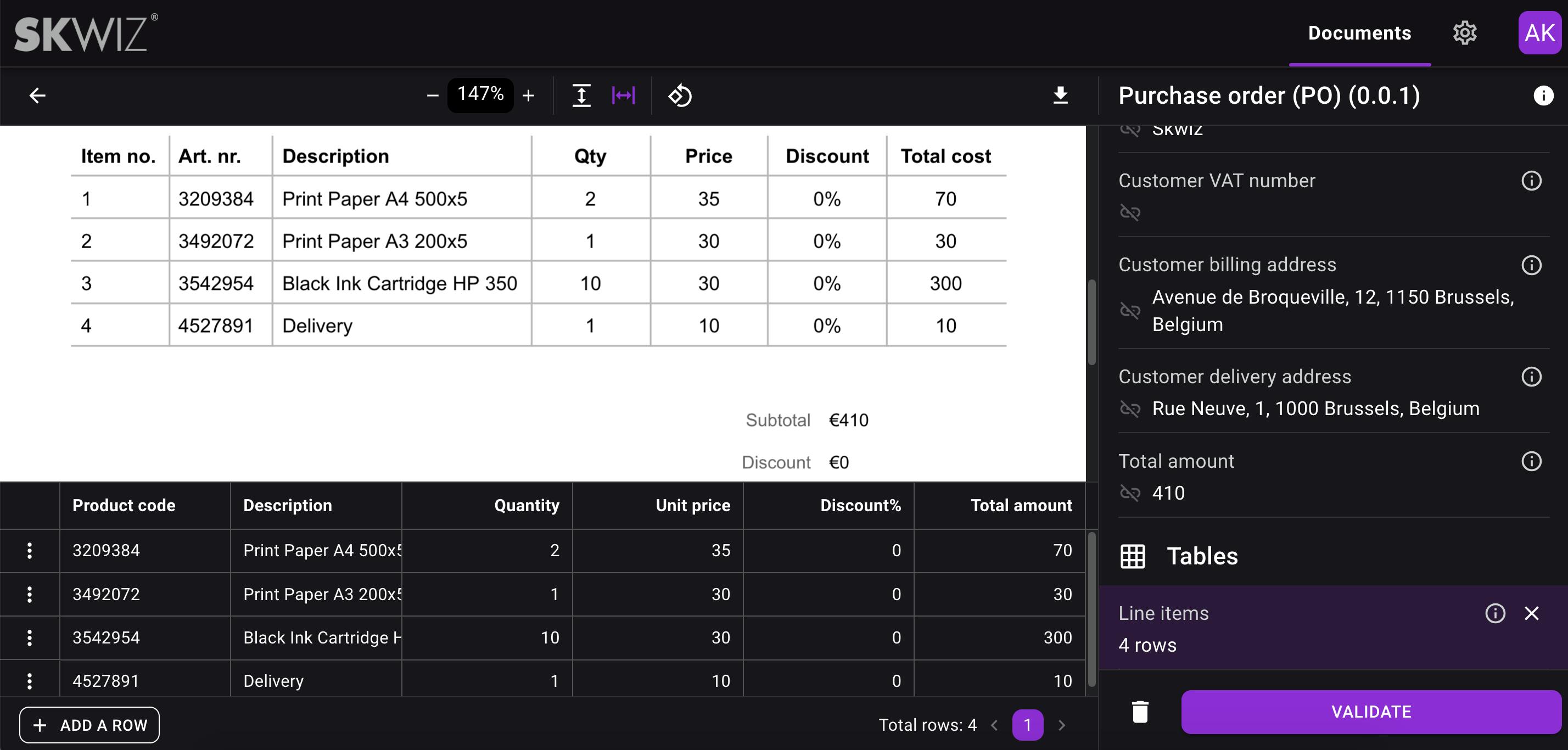
Documentation
Skwiz has its own documentation, which in a first version is focused on helping you optimize the quality of your document extractions. This can be achieved by following the naming conventions, understanding the various field types available, and providing additional instructions for each field that requires optimisation.
API & its documentation
The Skwiz API offers asynchronous extraction. You can generate multiple API keys.
The following routes are available and described in the API documentation:
Asynchronous extraction: upload your document
Get document extractions: retrieves the status and extracted values (if available) of 1 document
Get documents status: retrieves the status of one or more documents
We will soon add a webhook so that you’ll be able to receive the data from each document as soon as it’s extracted or validated in Skwiz.
Manual export
You can manually export the extracted data from documents into excel or JSON files, along with the documents themselves. To do this, simply select one or multiple documents from the document overview and click on the export icon located above the list. Alternatively, you can directly export a document’s data from the document validation screen.
Document auto-deletion
Skwiz’ main purpose is to extract information from documents and provide you access to the data, without serving as a system of records. By default, documents are stored for 2 months, providing you with sufficient time to validate the documents and access the extracted data. You can reduce the retention period in the settings, and documents can be manually deleted at any time from the document overview.